So, I’ve made quite a few posts lately because we are near the time when teachers will be working through the very confusing topic of inferential statistics in Common Core Algebra II. With so little guidance from NYSED on the matter, we are left to sift through sample problems, standards, and (ugh!) the Modules. Ultimately, inferential statistics is a topic that is much, much too large to simply squish into Algebra II.
If anything, the state should almost consider renaming the course Algebra 2 with Statistics if they are honest about the content.
What’s ultimately very difficult is that the CC Standards and the GAISE report for inferential statistics emphasize (in fact insist) on using statistical simulation instead of formulas to develop things such as confidence intervals and margins of error. The theory, at least, is that the formulas are much more understandable (in future courses) if students develop a more intuitive grasp of inferential statistics by using probabilistic thinking generated through simulation.
I’m not sure I even understood what I just typed.
Still, I do get the idea of simulation. If we find that a random sample of 50 people have an average television view time per week of 18 hours per week with a standard deviation of 3.5 hours per week, it is unlikely that the population as a whole has an average view time outside of the interval 17 to 19 hours. Here are the results of running our online simulator where I assume a population mean of 18 with a standard deviation of 3.5 and a sample size of 50. Click on the image to see it more clearly:
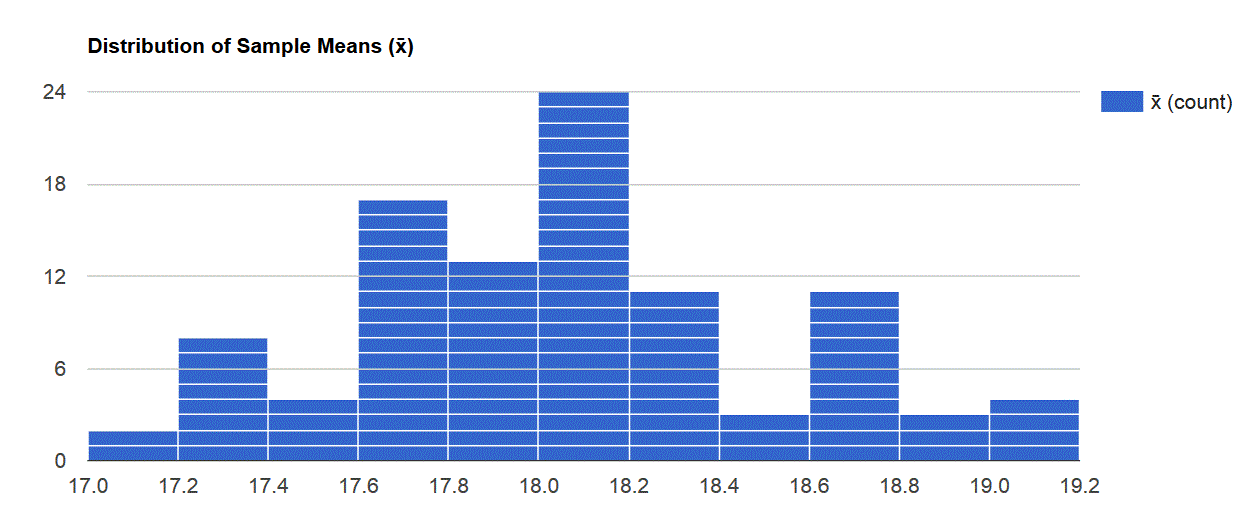
Notice, there are no sample means under this simulation that fall outside of the range 17.0 to 19.2. This, in fact, would be a rough approximation for our confidence interval and half the width between these, i.e. (19.2-17.0)/2=1.1, would be a rough width for our margin of error. By the way, the actual margin of error is a theoretical 0.99 (2*stddev/sqrt(n)). Here’s a link to that simulator and our other two as well:
Sample Normal Distribution Web Based App (NORMSAMP)
Sample Proportion Simulator Web Based App (PSIMUL)
Difference of Sample Means Web Based App (MEANCOMP)
Now, there are more formulaic ways to grind out confidence intervals and margins of error. And, let’s face the fact, the state isn’t going to make them do statistical simulation on the Regents exam (June 1st); what it will do is make them interpret the results of those simulations. I’ve created three new lessons that weren’t in Version 1 of our Common Core Algebra II text. I’ve posted them before, but I’m going to do it again, with the answer keys. Should you spend time on these more formulaic approaches to confidence interval and margin of error? That, I will leave to your professional judgement. I do tie the statistical simulation into these lessons, so that will get reinforced. Here are the lessons and their keys.
CCAlgII.Unit #13.Lesson #8.The Distribution of Sample Means
CCAlgII.Unit #13.Lesson #9.The Distribution of Sample Proportions
CCAlgII.Unit #13.Lesson #10.Margin of Error
CCAlgII.Unit #13.Lesson #8.The Distribution of Samples Means.Answer Key
CCAlgII.Unit #13.Lesson #9.The Distribution of Sample Proportions.Answer Key
CCAlgII.Unit #13.Lesson #10.Margin of Error.Answer Key
Sorry, but no videos on these yet. I am looking to do them before the end of April (so well before June 1st). Maybe consider flipping these or just giving kids the option to watch them and learn the content.



Thank you for using eMATHinstruction materials. In order to continue to provide high quality mathematics resources to you and your students we respectfully request that you do not post this or any of our files on any website. Doing so is a violation of copyright. Using these materials implies you agree to our terms and conditions and single user license agreement.
Thank you for using eMATHinstruction materials. In order to continue to provide high quality mathematics resources to you and your students we respectfully request that you do not post this or any of our files on any website. Doing so is a violation of copyright. Using these materials implies you agree to our terms and conditions and single user license agreement.
The content you are trying to access requires a membership. If you already have a plan, please login. If you need to purchase a membership we offer yearly memberships for tutors and teachers and special bulk discounts for schools.
Sorry, the content you are trying to access requires verification that you are a mathematics teacher. Please click the link below to submit your verification request.